The JavaScript Call Stack & Event Loop Simplified

G
Front-end Engineer developing bugs with JavaScript, TypeScript, React & Next.js and Vue & Nuxt. Casually writing dev articles.
Search for a command to run...
Front-end Engineer developing bugs with JavaScript, TypeScript, React & Next.js and Vue & Nuxt. Casually writing dev articles.
No comments yet. Be the first to comment.
In this article, we will cover most of the methods that allow us to manipulate arrays including transforming, searching, and iterating over them.

Regular Expressions could be very tricky and hard to comprehend, so in this article we'll discuss the major things to get you up-to-speed with creating and working with Regular Expressions in JavaScript. So, what's a Regular Expression? A regular exp...

An abridged roadmap to help you become a front-end web developer, including learning resources.

Let's take a look at CSS grid and how we can use it to implement our own 12-column layout grid.

One of the concepts that most beginners skip when learning JavaScript is how the JavaScript engine runs code on a single thread, and how browsers handle asynchronous tasks. By understanding the Call Stack and Event Loop, you'll learn how tasks are handled by the JavaScript engine, and hence, start writing non-blocking code.
Now, why should you care? Here are three reasons:
You get to understand how JavaScript works under the hood.
It helps in debugging code.
Based on my research, questions on the Event Loop and the Call Stack come up in interviews.
We'll be using two important terms in this article: stack and queue; so, it's necessary that I throw some light on them before the action starts.
A Stack and a Queue are data structures that are supported in most, if not all, programming languages. If you already know what they are feel free to skip this section.
In computer science, a stack is an abstract data type that serves as a collection of elements, with two main principal operations: push, which adds an element to the collection, and. pop, which removes the most recently added element that was not yet removed. - Wikipedia.
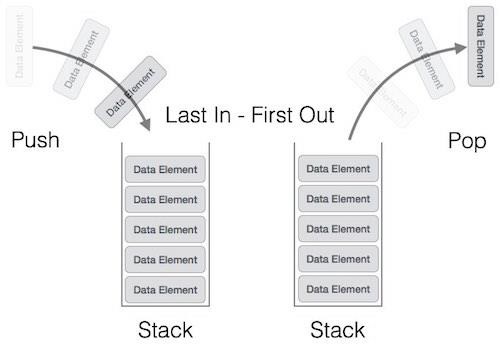
Take note of the text Last in - First out in the presentation above. Stacks use the Last In, First Out principle in managing a list (or array) of objects (elements), where the last item pushed onto the list is the first to be popped off. Makes sense?
A common example of a stack is a pile of books:

In order to add a new book to the pile of books, you put it on top, making it the last book; but in order to take the first one, Literature, you'd have to take off the last ones: Maths, History, Science.
So, the last item in the stack is the first to go out of it. That's the main idea behind the stack data structure.
In programming, a queue is a data structure in which elements are removed in the same order they were entered. This is often referred to as FIFO (first in, first out). - Webopedia
Unlike stacks, a queue uses the First In, First Out (FIFO) principle when managing lists. In this case, the element or object which is first added to a list, is the first to go off the list.
A real-life example is a queue of people looking to meet the doctor at a hospital. The person who comes first sees the doctor first, right?
Queues have the idea of first come, first serve.
Since this isn't a data structures article, let's get to why we're here.
In computer science, a call stack is a stack data structure that stores information about the active subroutines of a computer program - Wikipedia.
Here, "active subroutines" simply means "active functions" or "invoked (running) functions".
In JavaScript, the call stack is a single-threaded stack of function invocations in an active JavaScript program.
The call stack is basically a list of functions which have been invoked but aren't done running. The fact that it is single-threaded means only one thing is happening at a time.
Whenever we call a function (e.g. funcA), it gets pushed onto the stack as a stack frame. A stack frame is a memory location on the call stack.
So, if this particular function depends on another function (e.g. funcB), as in it invokes funcB in its block, then funcB gets pushed onto the stack too, right on top of the function which invoked it; in this case funcA.
// definition for funcB
function funcB() {
return "End of B";
}
// definition for funcA
function funcA() {
// funcB is called inside funcA
let str = funcB();
}
// now, funcA is called
funcA();
Now, here's a visual representation of how the JavaScript engine runs this script:

Okay, let's digest this.
First and foremost, where the heck is the main() function coming from, and how did it get its own stack frame? When a script (JavaScript code) is executed, the JavaScript engine creates a Global Execution Context, which is denoted by global() or main() function, which gets pushed onto the call stack. Thereby, becoming the first stack frame. We're not responsible for this - the JavaScript engine is.
In the code we wrote, only funcA() was invoked globally (on the last line). This invocation creates a Function Execution Context for funcA() and pushes it onto the call stack, and it starts being executed.
In the funcA() function, funcB() is invoked - where its returned string is stored in the variable str. At this point, a Function Execution Context is created again for funcB() and a stack frame is created for it and gets pushed onto the call stack.
Inside funcB(), every task (or code) is run until the last line (in our case, the return statement) which marks the end of the function. On this note, the function exits and is popped off the call stack. Since the call stack is a stack data structure, the last item goes out first (Last In, First Out). Therefore, funcB() is the first to be popped off the call stack.
When funcB() finishes executing, its returned value is obtained by funcA() which is stored in the str variable. And since the variable initialisation is the last line of funcA() it marks the end of the function, and hence causes the stack frame of funcA() to be popped off the call stack.
Now, since there are no more functions to be executed by the JavaScript engine, the Global Execution Context exits and main() or global() is popped off the call stack too, leaving it empty.

If the image above isn't big enough just open it in a new tab and zoom in.
Before you get overly excited, this section isn't about the forum stackoverflow.com 😅.
There's a maximum number of stack frames that can occupy the call stack.
If this limit is exceeded, a stack overflow occurs. In other words, the JavaScript engine throws a RangeError exception (in Chrome), or InternalError exception (in Firefox).
But how could this ever happen?
A common way a stack overflow could occur is when a recursive function is executed without an exit condition.
A recursive function is any function which invokes itself in its definition block.
When such a function is invoked and no condition is provided for it to stop infinitely calling itself, the stack size limit is exceeded and a stack overflow occurs.
Here's an example of a recursive function which has no exit condition:
function example() {
// calling the same function inside its block
example();
}
// now call the function
example();
Copy the code above and run it. Check the developer console and you'll see an error which looks like this (Chrome):

Learn more about recursive functions here.
I mentioned earlier that JavaScript is single-threaded, and that it runs one task at a time.
So, how does it handle asynchronous tasks?
JavaScript code is run from top to bottom; tasks that are written first are executed first. However, this is different from asynchronous tasks.
Basically, asynchronous tasks are those that take some time before they complete. An example is fetching data from a remote server. Another instance is writing setTimeout() to invoke a function after several milliseconds.
Let's examine this code:
console.log("start");
// print "middle" after 1 second
setTimeout(() => {
console.log("middle");
}, 1000);
console.log("end");
Result:
start
end
middle
As you'd expect, the setTimeout() fired its callback after a second, but then the browser skipped it and executed the console.log() at the end before coming to execute the callback in the setTimeout().
How does that happen under the hood when we know JavaScript has one call stack and is single-threaded?
First of all, the first console.log() is pushed onto the call stack (after the global execution context, of course).

And after it logs to the console, its stack frame is popped off the call stack.

Then, the setTimeout() is pushed onto the call stack.

Browsers come with their APIs (Application Programming Interfaces), such as setTimeout, the DOM, XMLHttpRequest, etc. These APIs aren't provided by the JavaScript engine and hence, it doesn't know how it can execute such code. Therefore, the engine immediately marks it as complete (without running it), pops it off the call stack, and lets the browser or Web API handle it.
So, our setTimeout() is popped off the call stack so the Web API handles it, and then a timer is placed on its callback by the Web API.

At that point, since it has been removed from the call stack, the JavaScript engine continues executing the code, and the last console.log() is pushed onto the call stack and executed, whilst the setTimeout() callback is being handled by the Web API.

The moment the provided time on the setTimeout() expires, in this case, 1 second, the callback is pushed onto the Callback Queue.

And obviously, by now, the last console.log() had already been executed and popped off the call stack, meaning the script is done running.

Remember what the queue data structure is?
The Callback Queue is a first-in-first-out data structure. Meaning, the first function which it takes is the first to go out of it.
Why didn't the Web API push the callback function directly onto the call stack? The reason is that, by the time the timer on the callback expires, the call stack may be busy executing functions.
So, the asynchronous code is enqueued on the Callback Queue, waiting to be pushed onto the call stack by the event loop.
The event loop is an endless loop which has only one goal: push tasks (from the callback queue) onto the call stack when the call stack is done running the script.
The event loop keeps checking both the call stack and callback queue; if the call stack is empty, it checks if there are any queued tasks on the callback queue. If there are any, it pushes them onto the call stack.
So, now that the JavaScript engine is done executing code and the call stack is left with no more code or functions to execute, the event loop takes the callback from the callback queue and pushes it onto the call stack to be executed.

The callback is run, and the engine notices it calls console.log(). It takes that and runs it too, pushing it onto the stack.

After it logs the string "middle" to the console, it is popped off the call stack.

Since the callback is done executing, it is popped off the call stack also.

That's how we got this result:
start
end
middle
Rewrite the setTimeout() function with a time of zero milliseconds, and run the code.
setTimeout(() => {
console.log("middle");
}, 0);
Zero milliseconds means no delay, right? We'd expect to see the string "middle" before "end" but no, the same result is yielded:
start
end
middle
This is because the setTimeout() is a Web API. Therefore, before it's executed, it has to be processed by the browser, and then enqueued in the callback queue, where it waits until the call stack is no longer executing functions, and then it's pushed onto the call stack and executed.
This marks the end of another article. If you're still scratching your head I suggest that you take some time off, bookmark the page, and come back later to read again.
If you like the article, don't forget to react, share, and follow me or subscribe to my newsletter so you don't miss my future articles.
Thank you!